Web3 Needs A Blockchain Data Lakehouse, And We’re Building One

Hyperline
Admin
Feb 28, 2024
Personalization powers the entire Web2 experience.
It could be something as simple as trying to find the perfect weekend binge on Netflix or getting recommendations from Amazon for accessories that you’re going to need for your recent purchase. Or even Airbnb giving you more reasons to take a break. And it works!
One of the greatest achievements that companies like Netflix have pioneered in the last decade is perfecting the art of how user interaction data, preferences, and behavioral insights can be leveraged to increase engagement and outcomes — and it’s a strategy that has built category leaders.
The numbers don’t lie.
Netflix’s recommendation system accounts for 80% of the content streamed on the platform, powered by an algorithm that uses over 1300 clusters. In their own words, their engineers have built a system that algorithmically adapts thumbnail artwork using Aesthetic Visual Analysis (AVA) and Contextual Bandits. Homepage rows, galleries, and title rows are also personalized based on user preferences.
A McKinsey report attributes up to 35% of Amazon’s sales to its recommendation engine and mentions that personalization can deliver five to eight times the ROI on marketing spend and increase revenue by more than 10–15% for businesses.
It’s easy to understand why personalization works so well. It turns generic platforms into experiential spaces where customers can build a unique connection.
With over 71% of customers expecting personalized interactions by default, this is a dealbreaker even in newer frontiers, like Web3 applications.
Why personalization in Web3 is broken.
To build personalized experiences and data-intensive applications, Web3 needs a unified platform that checks a few boxes:
Domain-specific context for Web3 data
Large-scale data storage
Real-time processing
Advanced analytics
If you’re building a complex application, let’s walk through how you’ll need to set up your data infrastructure today.
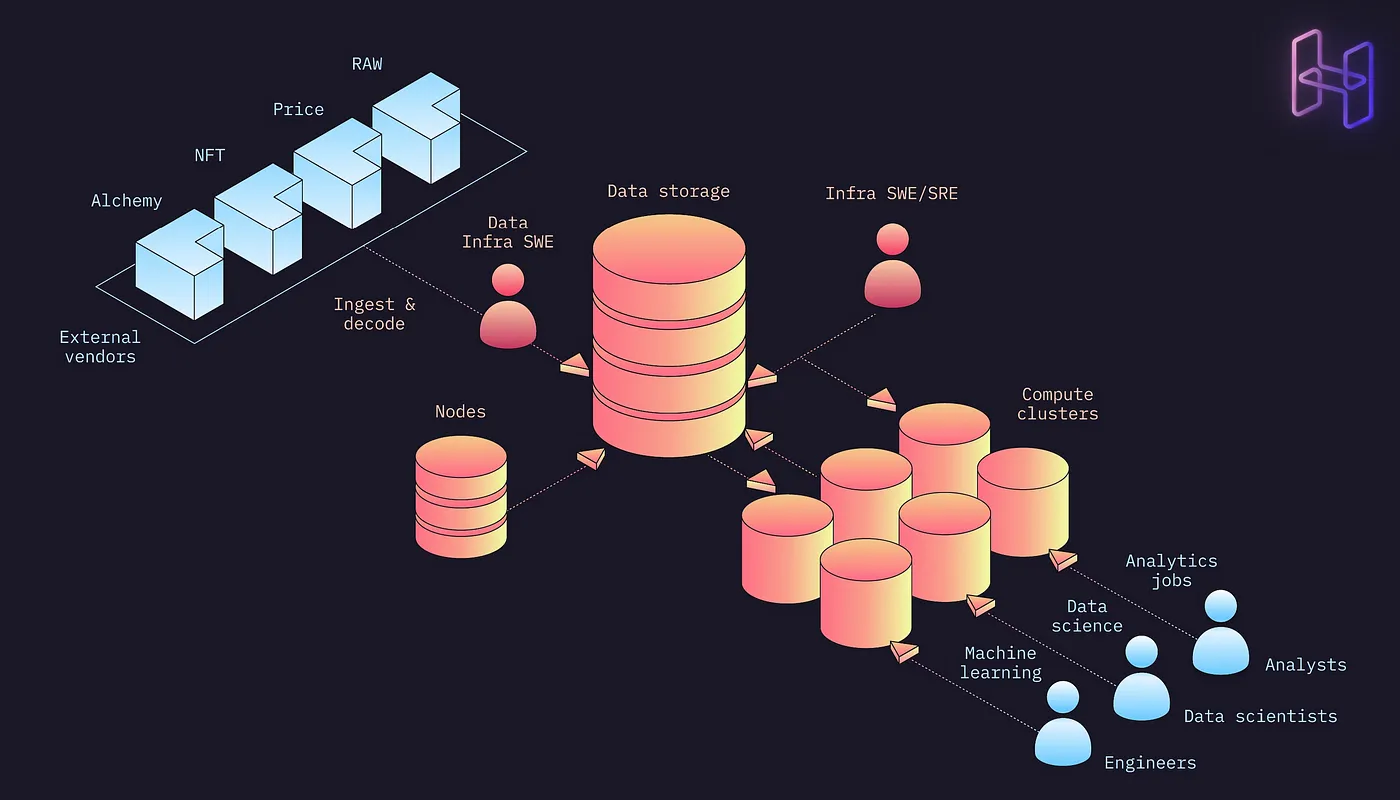
Step 1: Setup up blockchain nodes
You’ll need to start by deploying nodes to interact with blockchain networks. This isn’t just about tapping into the blockchain — it’s about ensuring secure, reliable access to real-time transaction data. These nodes help applications validate and relay transactions in a trustless environment and ensure that the data is correctly decoded and exposed.
Step 2: Source diversified data
Beyond the blockchain you’ll have to source off-chain data from multiple vendors. This is crucial for applications that need to integrate blockchain’s immutable records with dynamic data from external and internal sources to enable richer, more contextually-aware functionalities.
Step 3: Build ingestion and storage systems
You’ll then need to write data ingestion processes and establish storage infrastructure to architect a system that can handle the complexity and volume of data efficiently. This means — choosing the right storage solutions (like databases that support high read/write speeds and data integrity) and designing ingestion pipelines that can process data from disparate sources without hiccups.
Step 4: Hire specialized talent
Hiring data infrastructure experts is not just an operational necessity but a strategic one. To build data models and storage systems with the right optimization, you’ll need a team of subject matter experts. This is both time-consuming and expensive because remember you are competing with every other product team with similar needs.
Step 5: Configure compute clusters and DevOps
For advanced data analytics and integrated machine learning models, you’ll need to configure compute clusters for processing workloads and hire DevOps experts to manage these systems efficiently, and at scale. This is essential for any application feature that needs significant computational resources.
Step 6: Finally, focus on product development
Now that you’ve laid the groundwork, you can focus on what you set out to achieve initially — build an application that focuses on your customers’ needs.
Here’s the catch. If you’re a smaller product team you’ll be eating up limited resources to manage the operational costs, technical depth, sophisticated infrastructure, or long timelines that this process takes.
What you need is a plug-and-play solution.
We’re building a native data lakehouse for Web3.
Web3 has one significant advantage and that’s the open and accessible nature of on-chain data. While this democratizes how applications can easily access complex data, there’s still the hard part of building the infrastructure for ingestion and processing.
This is why we built Hyperline as a unified data layer for all Web3 applications.
Hyperline is Web3’s first and native data lakehouse that helps applications leapfrog the foundational challenges of data management and achieve incredible scale with none of the associated overheads. This removes the entry barrier for builders, essentially helping them focus on what matters — developing features that delight their customers.
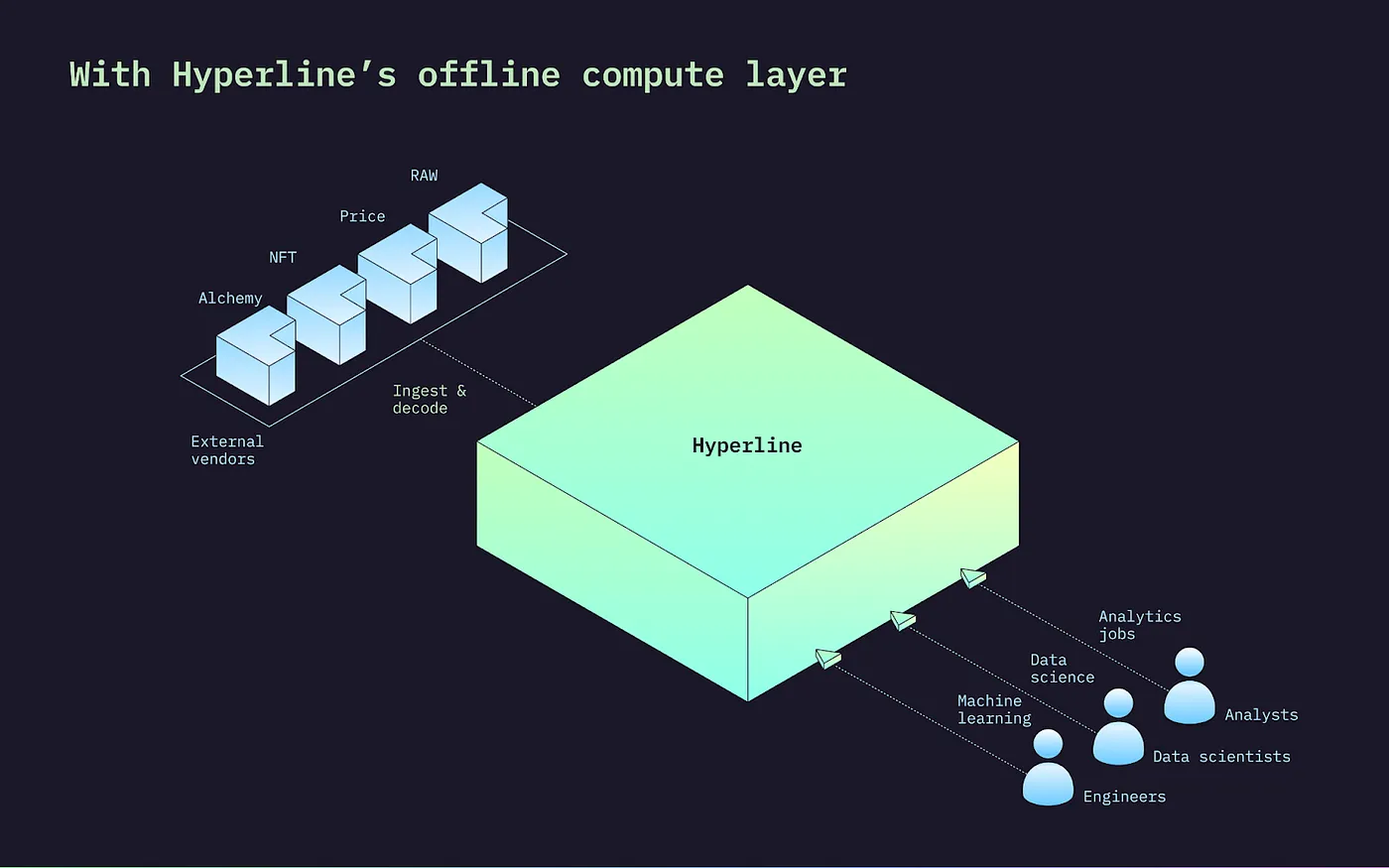
There’s an added advantage. Hyperline is an operational system, which means that:
It’s a single platform for analytics, data science, and machine learning workloads
It enables workflow automation via data processing pipelines for complex tasks
It is fully managed and supports multi-tenant and private cloud deployments
This opens up incredible new opportunities for applications to leverage data — for use-cases like personalized recommendations, advanced and predictive analytics, and fraud detection.
There’s a lot that apps can gain with this approach:
Simplified Data Management: Access to a centralized repository for storing structured and unstructured data. This eliminates the need for data silos and reduces complexity and overhead. Applications can directly tap into a comprehensive pool of data and focus more on product innovation.
Data Accessibility and Interoperability: By unifying blockchain and non-blockchain data in one layer, applications gain easier access to a wider array of data — which in turn, fosters greater interoperability among applications and services. Analysts, engineers, and data scientists can tap into richer datasets, for more nuanced and sophisticated features.
Minimal Operational Costs: It’s incredibly expensive to deploy nodes, source data from data vendors, hire specialized talent, and manage complex data infrastructure, so naturally, Hyperline helps product teams significantly improve their cost efficiency. By abstracting these complexities builders can focus on core product development over infrastructure and minimize operational costs.
Agility and Scalability: A data lakehouse is designed for scale and can accommodate increasing volumes of data with sustained performance. This is particularly important in the Web3 ecosystem, where applications deal with huge volumes of on-chain and off-chain data, and have to manage without extensive infrastructure overhauls.
And this is just the beginning.
The more we talk to customers and understand their challenges, we realize that the open nature of blockchain data isn’t as accessible as it should be. This throws up some interesting questions:
Why should teams rely on their vendors, when Web3 is fundamentally a trustless environment?
Shouldn’t developers be able to build applications faster using insights from a shared data layer rather than recreate the wheel for every organization and application?
These are questions that excite us and ones that we hope to answer real soon.
But that’s for another post, so stay tuned for updates!

