Supercharging On-Chain Analysis with Hyperline | Octan Network

Hyperline
Admin
Jul 3, 2024

Octan Network is building Web3’s Reputation Ranking System (RRS), an engine that employs Page Rank algorithms to quantify reputation scores of users and applications in Web3. Since 2019, the team has been studying Google’s PageRank to assist organizations in extracting insights from on-chain activity.
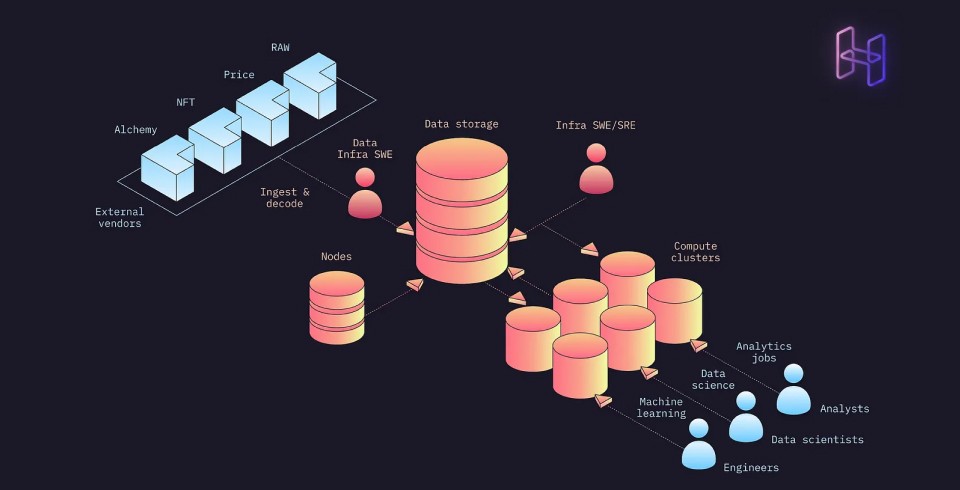
Hyperline is Web3’s first data lakehouse, enabling analysts, data scientists, and product engineers to more quickly and efficiently build intelligent applications in web3.
Introduction
Octan Network needed a way to reduce the costs of building and accelerate the development of their Web3 Reputation Ranking System (RRS). Like many teams, they were cobbling together disparate data sets, running research on their local machines, and eventually building production pipelines once they completed research. For the first version of their service, this made sense, however, they were running into bottlenecks across all three phases of development as they looked beyond the first version of their product.
The Challenge
Octan successfully built the first version of their Reputation Ranking System (RRS) like most data-products startups had: they cobbled together the necessary data, conducted their data science analyses locally, and built a basic pipeline that would allow them to turn their research into a product. From the beginning, however, Octan knew that the first version of their RRS could always be improved but knew that the end-to-end process they followed would not work for long. They needed a way to accelerate their research and development of subsequent versions of the product. All three areas of development were taking too much time from the core development and between Data Science and Data Engineering, the team wanted to go faster.
Data Acquisition: Octan Network’s Data Science Team needed to go find new and novel data sets on an ongoing basis in order to add more features to the model and bring it to new chains. As any data scientist knows, the process of sourcing, cleaning, and normalizing data often accounts for up to 80% of data scientists time.
Research: The Data Science team was conducting all of their analysis locally but it was starting to break as they began to ingest more data than their — admittedly powerful machine s— could handle.
Production Engineering: Once the new features were added and the algorithm was refined, the data engineering team would effectively need to re-create the model through their production pipelines. This step took a significant amount of time to transfer knowledge and also QA the final product.
All told, Octan, like most data product startups, lacked accurate and reliable data-sources, robust data infrastructure and smooth Machine Learning Operations (ML Ops) capabilities which limited how fast they could develop and iterate.
Paven Do, CEO and founder at Octan, noted:
“Octan Network focuses on extracting new insights from tons of on-chain data. We’ve been conducting a huge amount of Data Science tasks, then transforming Research into product development. Fragmentation in data engineering processes results in long research and development cycles.”
The Solution
When Octan met Hyperline, the team was doing cutting-edge work but increasingly running into bottlenecks across these three phases of work. They initially turned to Hyperline to simply help with all things data related — namely, making data acquisition and normalization far simpler by using Hyperline’s Data Lakehouse. To start, Hyperline’s data-and-platform agnostic approach meant that the team was able to seamlessly link up all of their existing data sets — some from public sources and others generated internally — into the shared infrastructure. But more than that, Octan could now tap into other leading Web3 data sources including those from Google or Flipside Crypto. Having instant access to these high-quality data helped save the team weeks based on their previous, manual acquisition approach.
As soon as the data wrangling challenges were lessened, the team could focus on more innovative research and iterate on model development quickly. They can and did continue to run some analyses locally — using Hyperline as a simple data repository where they could extra data using SQL — but also began to extend some analyses to Hyperline’s Spark environement for more significant jobs and ultimately to Hyperline’s hosted Jupyter Notebooks for modeling their RRS algorithms. They were now able to answer what should have been simple questions rapidly— such as “which wallets are from centralized exchanges?” — directly within Hyperline.
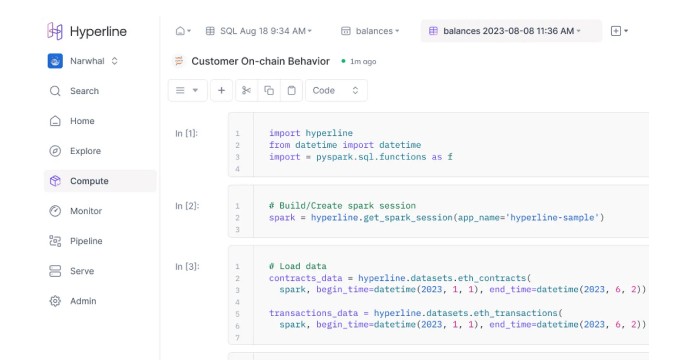
Modeling tasks that used to take a day or more now take a few hours, and in some cases even less. Multiple sources for transaction, price, token, and label data are available within the same platform, enabling efficient extraction and transformation. This allows us to optimize ML models quickly, leading to better insights and performance. Most recently, we used Hyperline to tune predictions of future user value from Octan’s credibly neutral algorithmic reputation score.”
– Scott Imig, Principal Scientist at Octan
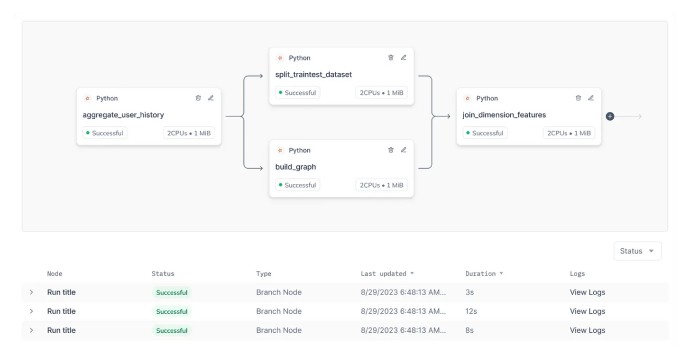
Finally, with the latest version of their model designed, it came time to take it into production. This is where the team found that Hyperline could really shine as a fully functional MLOps platform. Up to this point, Hyperline primarily benefited the Data Science team but now the Data Engineering team could engage and see the exact code of Data Science saving significant communication back-and-forths. Octan’s data engineering team could now release a new model in half the time compared to the previous work cycle.
According to Paven Do, founder of Octan Network:
“Hyperline cut the time from research to product deployment in half. This allowed us to save time and money and deliver our cutting edge Reputation Ranking System to the market far more quickly than we originally intended.”
Conclusion
All told, Octan was able to iterate on the second version of their Reputation Ranking System on Hyperline with significant time saving of nearly 50%, all while allowing their Data Science team to extend their analyses with more expansive data sets that helped enhance their models. Hyperline was not only an accelerator but a significant cost saver that allowed Octan to avoid wasting engineering cycles. Now running on production in Hyperline, the Octan team is looking forward to pushing the boundaries of what novel insights they can generate and how they can continue to serve the Web3 ecosystem.