Build v. Buy: How to Plan Your Web3 Data Infrastructure

Hyperlink
Admin
Apr 24, 2024
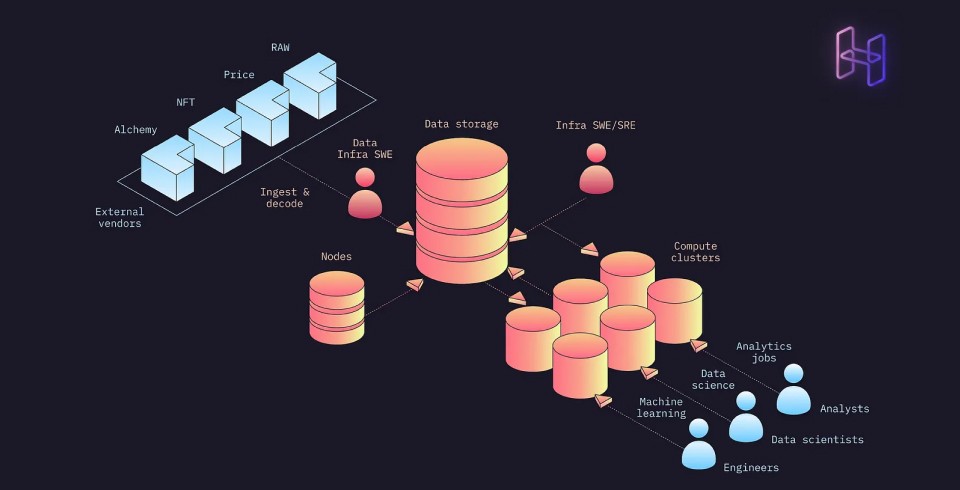
Web3 products face a big data problem from day one.
Instead of growing slowly and layering in big-data solutions later, mainly because of its open blockchain ‘database’, Web3 requires big-data-oriented solutions from the outset. Product teams are immediately tasked with having vast, varied data types like swaps, wallet interactions, smart contract events, and more that they’re required to interact with, understand, and in certain cases actually create. What’s more — the exponentially growing volume of on-chain data, off chain data sets, and disparate data vendors means that the ultimate task of analyzing — or doing computation — over these data sets is a herculean task.
For Web3 CTOs, this means that immediate investment in high-capacity data infrastructure is non-negotiable. This is where they hit the classic Build vs Buy conundrum.
The Build vs Buy Dilemma
If you’re a CTO, this classic dilemma is one you’re likely familiar with: should you leverage the benefits of a Web3-native data lakehouse like Hyperline, or build your own infrastructure from scratch in the hopes of optimizing it for your bespoke use case?
At a high level, the costs you will face are:
Initial Build Out Costs: The expenses — usually engineers — required to research, design, and build your infrastructure.
Recurring Maintenance Costs: Engineers and vendor costs needed to operate this system and enable downstream applications.
Opportunity Cost: The cost of time that comes from having your team focus on building infrastructure, and not your core application.
Teams with limited resources are constantly faced with hard decisions on how to allocate resources, which is why we’ve built Hyperline to help you.
At its core, Hyperline is a fully managed data lakehouse that eliminates the overhead of building and maintaining data infrastructure. Our platform helps you:
Offset the cost of hiring dedicated data infrastructure teams and specialized talent
Minimize data acquisition and data warehousing costs
Consolidate Analytics, ML, and Data Science workloads into a single platform
Minimize the costs of maintaining high-performance, secure, and reliable systems
Accelerate your team’s ability to test and iterate on innovative, core features
Immediately access blockchain, off-chain, and 3rd party data, regardless of where it is warehoused
Optimize your compute engine or integrate tools like Snowflake and Bigquery
But as a decision-maker, how do you run a cost-benefit analysis to validate this claim?
Decoding the costs of building your own data infrastructure
We’ve created this high-level ROI framework to help Web3 teams quantify the costs involved in building their own infrastructure, and understand the benefits of leveraging Hyperline.
Initial Build-Out Costs
Any team that is evaluating data infrastructure first needs to research the ideal solution for today and then move to design and build the corresponding solution. While the optimal data engineering team sizes for Web3 projects can vary, even smaller organizations need at least 2–3 data engineers who can effectively build and maintain scalable data platforms.
The costs typically show up in three sections:
Research: An individual or team usually spends one or more weeks evaluating requirements and possible technologies that can support the given use cases. At larger organizations, this process typically takes longer due to more requirements and cross-functional dependencies.
System Design: After the preliminary research, the team must come up with a functional architecture to support the given use cases. In reality, research and system design happen in tandem.
Development: Development is naturally the bulk of the time that goes into getting a data platform up and running.
Initial data platforms builds typically take 3–6 months and require a team of at least 2 data engineers with average US salaries of over $300k.
Put simply, Hyperline effectively eliminates these setup costs, giving you a ready-made platform that your team can start using on day one.
Recurring Maintenance Costs
Assuming you’ve built the platform, you will next face the ongoing cost of maintaining the service. This breaks out into the labor costs needed to monitor, fix, and scale the platform in addition to the underlying licensing costs needed to just operate the system. Specifically this breaks down as follows:
Licensing Costs
Data Licensing Costs: Includes paying for access to blockchain data via services like Alchemy, running and operating nodes, and buying data from 3rd party vendors.
Software Licensing: Regular fees for software platforms, database management, and integrating analytics tools like Snowflake and BigQuery.
Cloud Services or Server Hosting: A large portion of your spend will need to go to storage and compute costs in order to help meet your data availability, processing, and analytics requirements. This typically includes GCP, AWS, or Azure costs.
Additional Software Licensing: Regular fees for software platforms, database management, and integrating analytics tools like Snowflake and BigQuery that may go above and beyond core storage and compute. You will need to periodically invest in cybersecurity measures and tools to protect data integrity, data governance, and more.
Data service providers charge an average of ~$14,000 per year for a subscription that covers access to data sets, a dedicated warehouse for enhanced computing power, and integrations with various third-party BI tools.
Labor Costs
Engineering Staff: In addition to Data Engineers, who may need to continue to iterate and improve upon the core platform, site reliability engineers (SREs) are required to oversee ongoing maintenance and troubleshooting.
Administrative Costs: Personnel must monitor changes in underlying technology (eg. version updates) or regulations (eg. GDPR) that require changes in your data platform.
Maintenance: Blockchains specifically — but also other software — are continuing to evolve at a rapid rate with new ones coming up all the time. You will need to continue investing in your systems to keep up with the changing landscape and manage integrations with existing & new vendors. This will require expensive data engineers. In addition, you will need to have site reliability engineers (SREs) to monitor system performance and SLAs.
For labor, salaries of US-based SREs and Data Engineers is $164k and $300k, respectively and for context a leading online marketplace for digital assets and NFTs has a dedicated team of 7 engineers maintaining their infrastructure with minimal downtime, costing them just over $1M annually.
As a fully-managed and enterprise-ready platform, Hyperline eliminates the need for hands-on upkeep with automated maintenance for routine tasks like data backups, scaling, and updates. Investing in automated response mechanisms can significantly reduce downtime and preemptively address potential failures for simple analytics workloads all the way to complex, productionized ML pipelines.
Opportunity Costs
Lastly, the simple time it takes in delaying other technical initiatives is not to be overstated. Whether you’re an early stage start-up fighting to get to product market fit or a large enterprise organization, the decision to invest in building incremental infrastructure comes at the cost of not building something else. This is harder to quantify empirically but we know that there are many hidden costs that come from prioritizing other things such as:
Product Development Delays: If building data infrastructure is not core to your product, building this distracts the team from taking on higher-ROI projects.
Productivity Loss: Diverting data scientists to focus on building data infrastructure, for example, or diverting other engineers’ tasks they’re less suited to, will mean you’re not getting the full value out of these employees.
Lack of Agility & Technical Debt: The more infrastructure you need to build and maintain, the less nimble your teams will be to adapt to market changes or shifts in priorities.
For these reasons, Hyperline will allow organizations to more quickly realize the value of high-impact functions like data science and ML, and allow even existing data engineers to do far more with less. We’ve heard from our customers that bringing in Hyperline has allowed their data science and ML organizations to create insights, models, and even production systems in just weeks, instead of around 6 months it took before bringing Hyperline onboard.
Conclusion
We believe that data-driven products are a key component needed for Web3 to live up to its potential, but that the bottlenecks — and frankly, sheer costs — of doing so have prevented many organizations from tackling opportunities in this space. However, we’ve built Hyperline to explicitly empower those technical leaders by shortening the time from idea to impact and radically lowering the cost to do so. We’ve helped build this for the last wave of Web2 titans and want to help you do it in Web3.
Interested in learning more? Get in touch!

