Hyperline is the only Web3 data science platform you need

Hyperline
Admin
Apr 5, 2024
It’s almost impossible to imagine modern technology companies like Meta, Netflix, or Amazon without their highly advanced, data-powered products. These companies built great core experiences around simple read-write functionality, but they ultimately won their markets by building the best recommendations and personalized product experiences. It kept consumers coming back and competitors a step behind.
As a case in point — Netflix’s recommendation system today accounts for 80% of the content streamed on the platform, powered by data and algorithms.
At Hyperline, we’re building a platform to usher in a similar revolution in Web3.
In our earlier post, we wrote about Web3’s personalization problem, and how teams can leapfrog traditional limitations with a data lakehouse like Hyperline that eliminates the need for extensive infrastructure and facilitates seamless data science workflows.
Because if you think about it, the basics for personalization are in place — from open and accessible on-chain data to secure and user-controlled systems. But for data scientists and AI/ML engineers, some significant roadblocks still haven’t been addressed.
What affects data science workflows today?
In our post on Web3’s personalization problem, we outlined some of the biggest challenges that data scientists and AI/ML engineers face when trying to build intelligent applications in the world of Web3. This includes::
Access and Querying Challenges: Accessing and querying Web3 data is uniquely complex, and given that data scientists have to interact with various blockchain data providers, nodes, smart contracts, and decentralized storage systems, each brings new and unique properties that require different analytics and data engineering solutions to manage.
High Infra Cost: While web3 data is public, building your own infrastructure to ingest, normalize, and analyze the data still requires a lot of time and money. Existing tools are ill equipped to the nuances of web3 requiring teams to invest hundreds of thousands of dollars in talent, tools, and custom built data platforms. All of this adds up and slows down your ability to start driving value from your data.
Scalability challenges: As the ecosystem grows, the data generated by applications will outstrip what can be done on your local machine. Scaling storage and processing requires cumbersome data-infrastructure build-outs that take months and require resources.
Data Integrity and Trustworthiness: While blockchain data is immutable and trustworthy, it’s hard to ensure the integrity and accuracy of off-chain data. Data scientists need robust processes and mechanisms to verify the provenance and validate both on and off-chain data before it can be safely relied upon within their analyses.
Data Fragmentation: Web3 data is scattered across L1& L2 blockchains, third-party vendors, and off-chain sources. This fragmentation makes it difficult to aggregate and normalize data creating challenges for tracking data provenance, governance, and ultimately the underlying analyses and decision-making that are derived from it.
How Hyperline’s lakehouse model bridges this gap
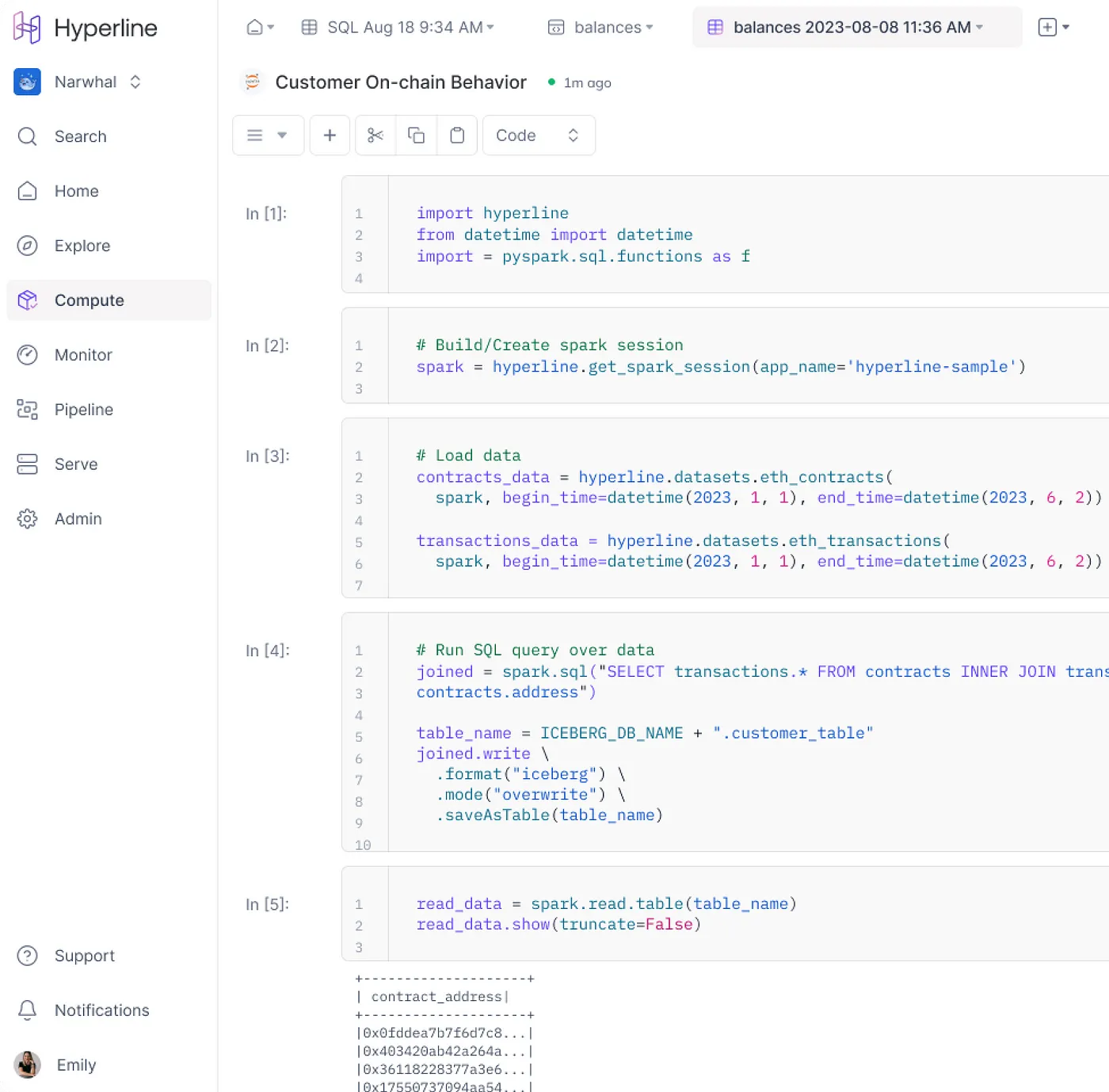
This is why we built Hyperline as Web3’s first data lakehouse, because our platform lets you streamline your workflows, access blockchain data seamlessly, and build advanced analytics and data products without the overhead of managing complex infrastructures.
Here’s how Hyperline can help:
Fully Managed Infrastructure: Get started without a data engineering team. Hyperline is fully managed and enterprise-ready, so you can forget about provisioning servers, configuring databases, or dealing with distributed storage quirks. Simply log in and Hyperline provides the data-engineering foundation you need to start working immediately.
Unified Compute: Hyperline provides a complete and headless compute environment tailored for blockchain analytics. With Jupyter, SQL editors, Python/R built in natively, it’s simple to get started and begin scaling out as needed.
Instant Data Access: Our lakehouse approach tackles data fragmentation across platforms by consolidating third-party and private data through cross-chain and multi-chain integrations. You get comprehensive access to DeFi, NFTs, and all on-chain activity through a single source. You can also simply connect and bring any data source you want — from S3 and Postgres to Google Cloud Storage to Snowflake.
Taken together, these factors have allowed users of Hyperline to radically reduce the cost and speed at which organizations can start building intelligence into Web3.
Where Hyperline is being used today
After being in beta for only two months, we’ve seen customers dramatically accelerate their ability to analyze, test, and innovate on new Web3 based data models that are powering applications in numerous ways. These Data Scientists are building powerful new mechanisms that are pushing Web3 and the ecosystem forward. Some of these include:
Page-rank Style Reputation Algorithms
Hyperline currently powers the page-rank algorithms of a Web3 pioneer building a first-of-its-kind reputation ranking system to evaluate the trustworthiness of wallet addresses. This ongoing effort paves the way for enhancing on-chain functionalities for verified addresses, fostering a more trusted and secure ecosystem.
Simulation Frameworks for Automated Market Makers (AMMs)
We’re helping a permissionless lending protocol leverage Hyperline for advanced testing and simulations of automated market maker performance under various conditions. This initiative is currently accelerating their development and deployment, and shortening the time to market for their DeFi products.
Recommendation Engine for Consumer DeFi
In the DeFi optimization space, Hyperline currently enables a platform dedicated to optimizing decentralized finance (DeFi) yields. Through Hyperline, the team is developing advanced recommendation algorithms that help users navigate and optimize their yield strategies, making it simpler for them to maximize their investments.
Farcaster Analytics & Monitoring
We’re helping a team develop and layer analytics and predictive models over the Farcaster ecosystem. These models analyze posting patterns and provide follower recommendations within the network, enhancing user engagement and fostering a more connected ecosystem.
Conclusion
In summary, Hyperline is changing the game for Web3 products and leveling the playing field, making it quicker and easier for early-stage teams to integrate the latest data science and machine learning innovations. We’re excited about helping our customers build the next generation of products in this space and can’t wait to share more as we continue building the product and growing our community.
Curious to see how it works? Checkout our site and get started on a free trial.

